EES API workflow
eesyapi.RmdThe following article presents an example workflow of how, as an
analyst, someone might connect to the explore education statistics (EES)
API to collect data with the help of eesyapi in R.
As an overview, the stages you will likely need to follow are:
- Find the data set ID
- Query the data set meta data to identify filter and indicator IDs
- Design a query using the relevant IDs
- Post the query to the API
- Perform some post processing of the data
Finding a data set ID
Only some data sets on EES are available via the EES API. This is to maintain minimum standards around the API data catalogue.
Assuming you know the data set within a publication that you would like to query, you will first need to identify the data set ID code. There are two methods to do this, either a) via the data set’s page on the EES website or b) by querying the API itself.
Identifying a data set ID via the API
Finding a data set ID via the API is a two step process. First, you’ll need to find the parent publication ID and second, you’ll need to search the data catalogue within that publication for the data set.
Querying the publication list:
eesyapi::get_publications()This returns a list of all publications by ID and title (along with slug, summary and date last published). From this list, you can find the title of the publication that you’re interested in and pick out the associated publication ID.
For example from the test list, we can pick out “Attendance
API data”, which has an ID of
25d0e40b-643a-4f73-3ae5-08dcf1c4d57f. We can now use
this in the function eesyapi::get_data_catalogue() to find
all the data sets within that publication:
eesyapi::get_data_catalogue("25d0e40b-643a-4f73-3ae5-08dcf1c4d57f")This returns a data frame containing data set IDs and titles (along with a summary, the status and information on what’s in the latest version). The data set IDs can be used as shown in the following sections to get a given data set’s summary and meta data, and to query the data set itself.
Finding a data set ID on the EES website
As with any other data set, you can find an API data set in the EES data catalogue. If you know the name, you can filter the catalogue on this as normal. Not all data sets are accessible via the API, so to filter down to just those that are, click the “API data sets only” option as shown in the image below.
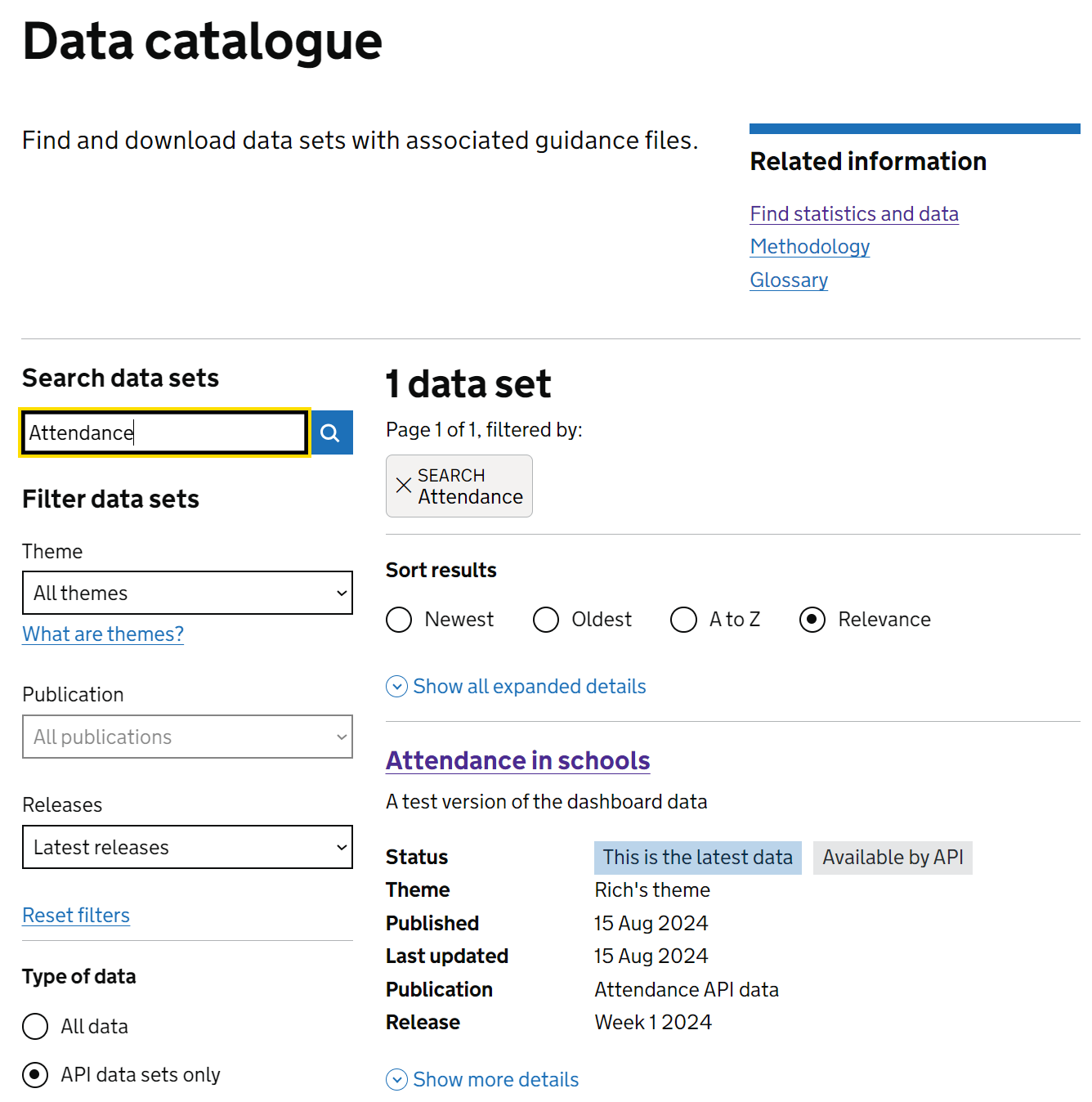
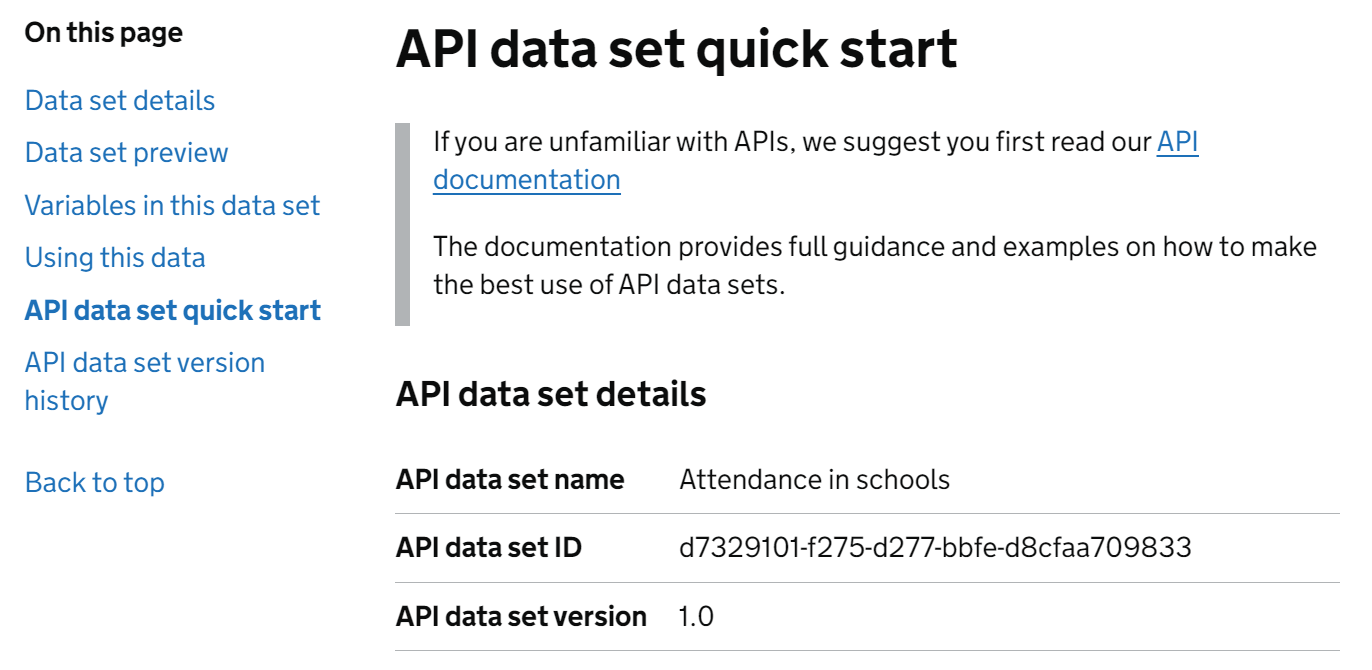
Once you’ve found the data set you need, then click on the title of the data set to be taken to it’s details page in the catalogue. On this page (pictured below), you’ll find the API data set quick start section, which gives the API data set name, API data set ID and API data set version. This API data set ID is what’s needed below to query the data set and its meta data.
Preview underlying data
In the EES API you have the option to preview the underlying data for a given data set. This bypasses the use of IDs, making it a simpler short-term option to explore the available data.
Using eesyapi, you can preview a data set using
preview_dataset() and providing the data set ID as
follows:
eesyapi::preview_dataset("57b69201-033a-2c77-a19f-abcce2b11341")This will return a data frame containing the first 10 rows of the data in the form that DfE analysts uploaded it to EES in.
While you can set n_max to Inf, and get the whole data set using
this, you should avoid relying on the preview_dataset()
function in your pipelines or dashboards and instead use it to explore
the data as you create your own custom query using
query_dataset().
If you only read the whole file in using the preview you risk:
- code breaking whenever element labels change
- reading in too much data into active memory, causing R to slow or even crash
Getting the data set meta data
When querying a data set via the API, column names (indicators and filters) and the options available within columns (filter items) are referenced using auto-generated ID codes (known as SQIDs). Therefore, in order to construct a query that involves selecting a subset of filter items or indicators, you’ll need to obtain the IDs associated with those elements.
All those IDs are stored in a data set’s meta data, which can also be
queried via the API. To get those IDs as well as details on what time
periods and geographic levels and locations are available in a given
data set, you can use the function eesyapi::get_meta(),
providing it with your data set’s ID. For example, to get the
“attendance in schools” data from the example attendance API data
publication, you can take the data set ID
57b69201-033a-2c77-a19f-abcce2b11341 and provide it as
a parameter to get_meta:
eesyapi::get_meta(dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341")This function returns a list of 5 data frames:
-
$time_periods: label, code and period of all available time periods in the data set -
$locations: geographic_level, code, label and item_id of all available locations in the data set -
$filter_columns: col_name and label of all filters in the data set -
$filter_items: col_name, item_label, item_id and default_item for all filter items in the data set -
$indicators: col_name and label of all indicators in the data set
The item_id values provided in $locations and
$filter_items are required to construct queries for
filtering a given data set, whilst time periods can be filtered on the
values in the $time_period code column.
In this example, let’s say we’ve run
eesyapi::get_meta("57b69201-033a-2c77-a19f-abcce2b11341")
and we want to filter our data set to obtain data for:
- the “Week 24” time period in “2024”,
- “York” and “England” from the geographies,
- “Absence” from Attendance status
- “Approved educational activity”, “Authorised” and “Unauthorised” from Attendance type
- Just the “Total” entries for “attendance_reason” and “day_number”
- And we want to see “Number of sessions” data values.
For this we would need the following codes / item_ids:
- “W24 2024”
- “arLPb” and “mRj9K”
- “qGJjG”
- “TuxPJ”, “cZO31”, “jgoAM”
- “AOhGK” and “9Ru4v”
- “tj0Em”
Note that whilst the above IDs are unique within a given item type
(e.g. filter_item), they are not necessarily unique between
types. For example, a given indicator could be assigned the
same ID as a filter_item in a given data set.
As a quick example of how you might quickly query the meta data for these codes, you could try the following example pieces of query code.
Geographies
eesyapi::get_meta(dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341") |>
magrittr::extract2("locations") |>
dplyr::filter(label %in% c("York", "England"))
#> item_id label code oldCode geographic_level_code geographic_level
#> 1 arLPb York E06000014 816 LA Local authority
#> 2 mRj9K England E92000001 <NA> NAT NationalFilter columns
Note that the col_id values here correspond to the col_id values in the filter items, which shows which column each item is availble in.
eesyapi::get_meta(dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341") |>
magrittr::extract2("filter_columns")
#> col_id col_name label
#> 1 5Zdi9 attendance_status Attendance status
#> 2 tdEm5 attendance_type Attendance type
#> 3 fyYFZ day_number Day number
#> 4 juAMt education_phase Establishment phase
#> 5 eNuSW attendance_reason ReasonFilter items
eesyapi::get_meta(dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341") |>
magrittr::extract2("filter_items") |>
dplyr::filter(
item_label %in% c(
"Absence", "Approved educational activity", "Authorised", "Unauthorised", "Total"
)
)
#> col_id item_label item_id default_item
#> 1 5Zdi9 Absence qGJjG NA
#> 2 tdEm5 Approved educational activity TuxPJ NA
#> 3 tdEm5 Authorised cZO31 NA
#> 4 tdEm5 Total fzaYF TRUE
#> 5 tdEm5 Unauthorised jgoAM NA
#> 6 fyYFZ Total AOhGK TRUE
#> 7 juAMt Total dPE0Z TRUE
#> 8 eNuSW Total 9Ru4v TRUERetrieving data from a data set
Using query_dataset()
The recommended go-to option for retrieving data is the
query_dataset() function. This provides options for
attaching a pre-made JSON file to a query, attaching a pre-made JSON
string or passing a set of IDs as parameters to create a query for
you.
Querying a data set using parameters
query_dataset() can be given a set of parameters to
build up a query for you. Behind the scenes it creates a JSON string
based on the parameters provided to it by the user. This inherently
limits the extent of the type of queries that you can perform, but it
should cover most basic use cases.
The parameters that you’ll can provide to build up your query are: -
time_periods - locations -
filter_items - indicators (required)
All these are optional, except for indicators which you
must always specify. If you don’t provide any of
time_periods, locations or
filter_items, then you’ll receive all rows from the data
set (although be careful, this may take some time for larger data
sets).
You don’t generally need to use the IDs for filter columns as the query only needs to know the options you want to select from those columns (filter items).
Using the parameters we obtained from get-meta above,
then we can create a query to return session count data for only
Approved educational activity,
Authorised and Unauthorised in the
Absences category, Nationally for
York in Week 24 in
2024, we would supply the following:
eesyapi::query_dataset(
dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341",
indicators = "tj0Em",
filter_items = list(
attendance_status = c("qGJjG"),
attendance_type = c("TuxPJ", "cZO31", "jgoAM"),
day_number = "AOhGK",
attendance_reason = "9Ru4v"
),
geographies = c("NAT|id|mRj9K", "LA|ID|arLPb"),
time_periods = c("2024|W24")
)
#> code period geographic_level la_name la_code la_oldCode nat_name nat_code
#> 1 W24 2024 LA York E06000014 816 England E92000001
#> 2 W24 2024 LA York E06000014 816 England E92000001
#> 3 W24 2024 LA York E06000014 816 England E92000001
#> 4 W24 2024 LA York E06000014 816 England E92000001
#> 5 W24 2024 LA York E06000014 816 England E92000001
#> 6 W24 2024 LA York E06000014 816 England E92000001
#> 7 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 8 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 9 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 10 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 11 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 12 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 13 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> 14 W24 2024 NAT <NA> <NA> <NA> England E92000001
#> reg_name reg_code attendance_status attendance_type
#> 1 Yorkshire and The Humber E12000003 Absence Authorised
#> 2 Yorkshire and The Humber E12000003 Absence Unauthorised
#> 3 Yorkshire and The Humber E12000003 Absence Authorised
#> 4 Yorkshire and The Humber E12000003 Absence Unauthorised
#> 5 Yorkshire and The Humber E12000003 Absence Authorised
#> 6 Yorkshire and The Humber E12000003 Absence Unauthorised
#> 7 <NA> <NA> Absence Authorised
#> 8 <NA> <NA> Absence Unauthorised
#> 9 <NA> <NA> Absence Authorised
#> 10 <NA> <NA> Absence Unauthorised
#> 11 <NA> <NA> Absence Authorised
#> 12 <NA> <NA> Absence Unauthorised
#> 13 <NA> <NA> Absence Authorised
#> 14 <NA> <NA> Absence Unauthorised
#> day_number education_phase attendance_reason session_count
#> 1 Total Primary Total 4221
#> 2 Total Primary Total 2292
#> 3 Total Secondary Total 4244
#> 4 Total Secondary Total 3290
#> 5 Total Special Total 113
#> 6 Total Special Total 80
#> 7 Total Secondary Total 1110294
#> 8 Total Secondary Total 881437
#> 9 Total Primary Total 1207541
#> 10 Total Primary Total 726508
#> 11 Total Special Total 94459
#> 12 Total Special Total 37099
#> 13 Total Total Total 2412294
#> 14 Total Total Total 1645044Some notes on the above:
-
indicators,time_periods,geographiesandfilter_itemscan all be supplied as vectors -c(...)- and will be interpreted asfilter(... %in% c(...)). -
filter_itemscan be supplied as a list to create more stringent cross-filter combinations, i.e. in the above example rows will only be returned for the specific combinations given across the 4 filters. -
geographiescan be supplied as a data frame to allow for more complex queries such as “give me all LAs in a given region”. The structure for this can be seen by callingexample_geography_query().
Querying a data set using a JSON file or string
If you’re familiar with using JSON and wish to just write your own
query from scratch, then you can use query_dataset() with
the json_query parameter as follows:
json_query <- "{
\"criteria\": {
\"and\": [
{
\"filters\": {
\"eq\": \"9Ru4v\"
}
},
{
\"locations\": {
\"eq\": {
\"level\": \"LA\",
\"id\": \"arLPb\"
}
}
}
]
},
\"indicators\": [
\"tj0Em\"
],
\"debug\": false,
\"page\": 1,
\"pageSize\": 10
}"
eesyapi::query_dataset(
dataset_id = "57b69201-033a-2c77-a19f-abcce2b11341",
json_query = json_query
)
#> code period geographic_level la_name la_code la_oldCode nat_name nat_code
#> 1 W25 2024 LA York E06000014 816 England E92000001
#> 2 W25 2024 LA York E06000014 816 England E92000001
#> 3 W25 2024 LA York E06000014 816 England E92000001
#> 4 W25 2024 LA York E06000014 816 England E92000001
#> 5 W25 2024 LA York E06000014 816 England E92000001
#> 6 W25 2024 LA York E06000014 816 England E92000001
#> 7 W25 2024 LA York E06000014 816 England E92000001
#> 8 W25 2024 LA York E06000014 816 England E92000001
#> 9 W25 2024 LA York E06000014 816 England E92000001
#> 10 W25 2024 LA York E06000014 816 England E92000001
#> reg_name reg_code attendance_status
#> 1 Yorkshire and The Humber E12000003 Attendance
#> 2 Yorkshire and The Humber E12000003 Attendance
#> 3 Yorkshire and The Humber E12000003 Attendance
#> 4 Yorkshire and The Humber E12000003 Absence
#> 5 Yorkshire and The Humber E12000003 Absence
#> 6 Yorkshire and The Humber E12000003 Absence
#> 7 Yorkshire and The Humber E12000003 Late sessions
#> 8 Yorkshire and The Humber E12000003 Possible sessions
#> 9 Yorkshire and The Humber E12000003 Attendance
#> 10 Yorkshire and The Humber E12000003 Attendance
#> attendance_type day_number education_phase attendance_reason
#> 1 Present 1 Secondary Total
#> 2 Approved educational activity 1 Secondary Total
#> 3 Total 1 Secondary Total
#> 4 Total 1 Secondary Total
#> 5 Authorised 1 Secondary Total
#> 6 Unauthorised 1 Secondary Total
#> 7 Total 1 Secondary Total
#> 8 Total 1 Secondary Total
#> 9 Present 1 Primary Total
#> 10 Approved educational activity 1 Primary Total
#> session_count
#> 1 13372
#> 2 407
#> 3 13779
#> 4 1806
#> 5 1080
#> 6 726
#> 7 487
#> 8 15585
#> 9 19472
#> 10 503FAQs
Why do you use IDs rather than the actual labels used in the data?
The IDs are intended to aid in future proofing for users that may develop automated pipelines that connect to the EES API. Labeling inevitably changes, for example if a “Total” entry is renamed to “All pupils” or “All schools” to add clarity. If the underlying content of that item stays the same, then automated pipelines will be required to still connect to the same item, therefore each item has an associated ID that will remain unchanged in a given data set as it is updated with new data over the subsequent releases, even if a renaming of a field occurs.