Databricks workflows
Please be aware that the Databricks platform is regularly updated and may look different from the guidance included on this site. If you notice any discrepancies between the content on this site and the Databricks platform, please let us know by contacting statistics.development@education.gov.uk.
Workflows user interface
Workflows allow you to build complex data pipelines by chaining together multiple scripts, queries, notebooks and logic. They can be used to build Reproducible Analytical Pipelines (RAP) that can be re-run with different parameters and have all inputs and outputs audited automatically. Other recommended uses of workflows are any data modelling tasks such as cleaning your source data and collating it into a more analytically friendly format in your modelling area.
Each step in a workflow is referred to as a task and each task has dependencies. They are accessible through the ‘Workflows’ link on the left hand menu of the Databricks UI.
Parameters can be set either at a workflow level or a task level and referred to in your scripts / notebooks, allowing you to reuse tasks / workflows for similar operations.
Each task can have dependencies on other tasks and can be set to only run under certain conditions, for example all of the previous tasks have completed successfully. These can be configured when tasks are added to the workflow through the user interface.
Workflows and tasks can also be configured to send notifications to users upon success or failure. These can be configured from the Workflow and Task user interfaces.
Workflows also come with robust support for GitHub and Azure DevOps repositories and can be set to run from a specific repo, branch, commit or tag.
Setting up a workflow
- You can create a new workflow from the Workflow page by clicking the ‘Create job’ button in the top right of the screen.
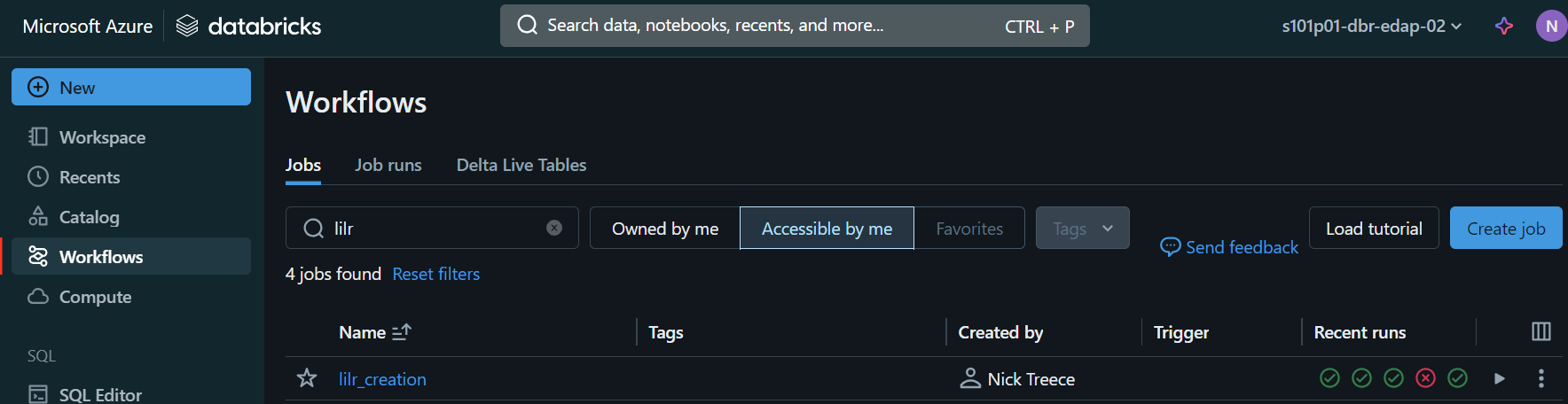
- You will then be presented with a page titled ‘New Job <timestamp>’ which you can edit to give the workflow a meaningful name.
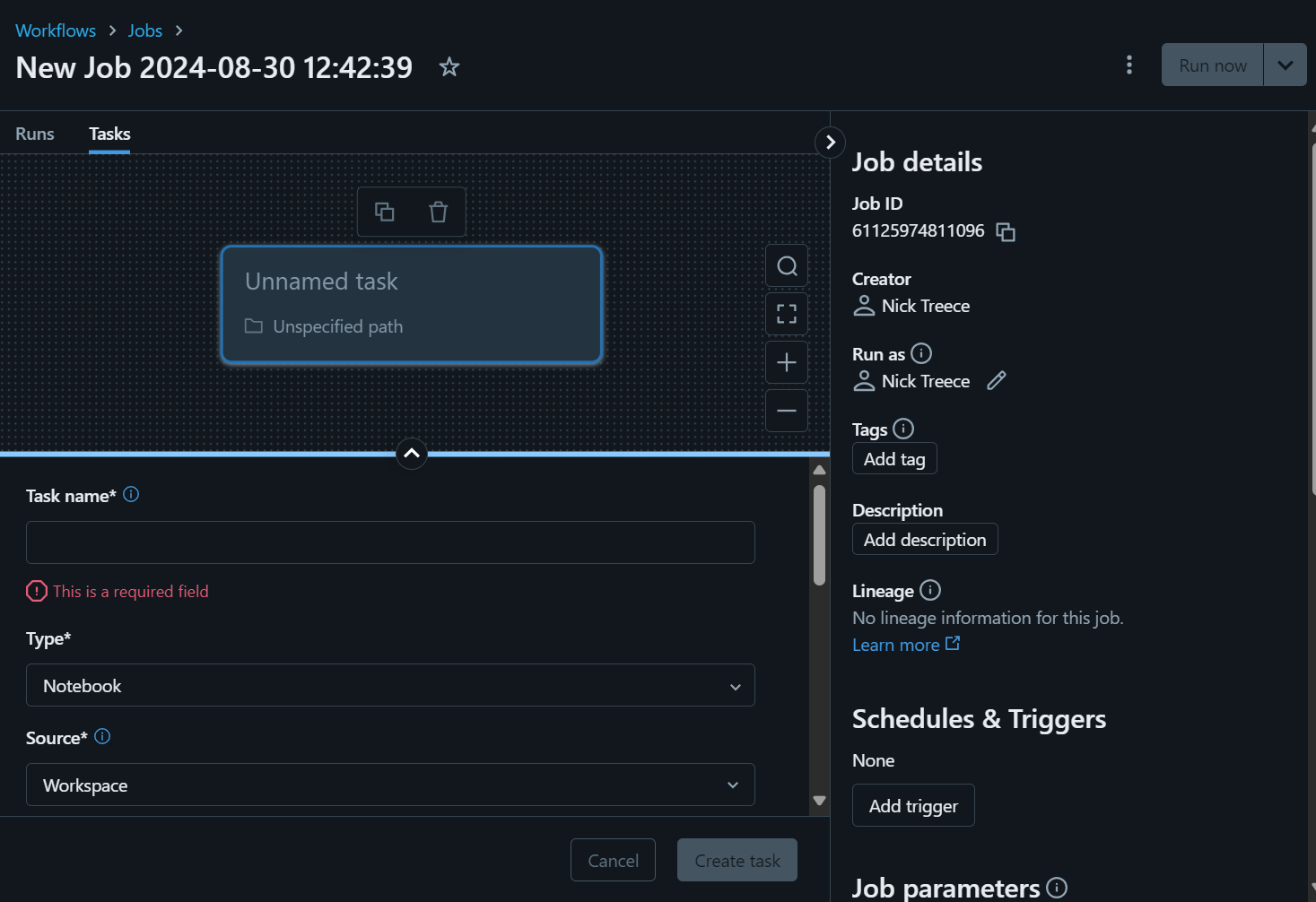
- The ‘Job Details’ pane on the right allows you to configure workflow level schedules and triggers, parameters which will be accessible to all tasks in the workflow, email notifications for successful / failed runs, and permissions on who can access and run the workflow. You can also add tags and descriptions to your workflow to help you keep track of them.
- In the task pane you can configure settings at an individual task level, including a unique name, the type of task (notebook, query, script, etc.) the source (your workspace, or a Git repository), the path to the code for the task and the compute resource the workflow should run on.
Any libraries or packages that the workflow depends on can be specified and these will be installed on the cluster by Databricks when it begins (not applicable to SQL warehouses).
You are also able to set task level parameters here which mean that you are able to reuse the same notebook for different tasks by setting different inputs. This allows you to create notebooks that serve as ‘functions’ from R or Python, or ‘stored procedures’ from SQL.
Here you can also setup notifications for the specific task. In addition you can specify the number of times a task should be retried if it fails, and a duration threshold for the task before forcing it to fail.
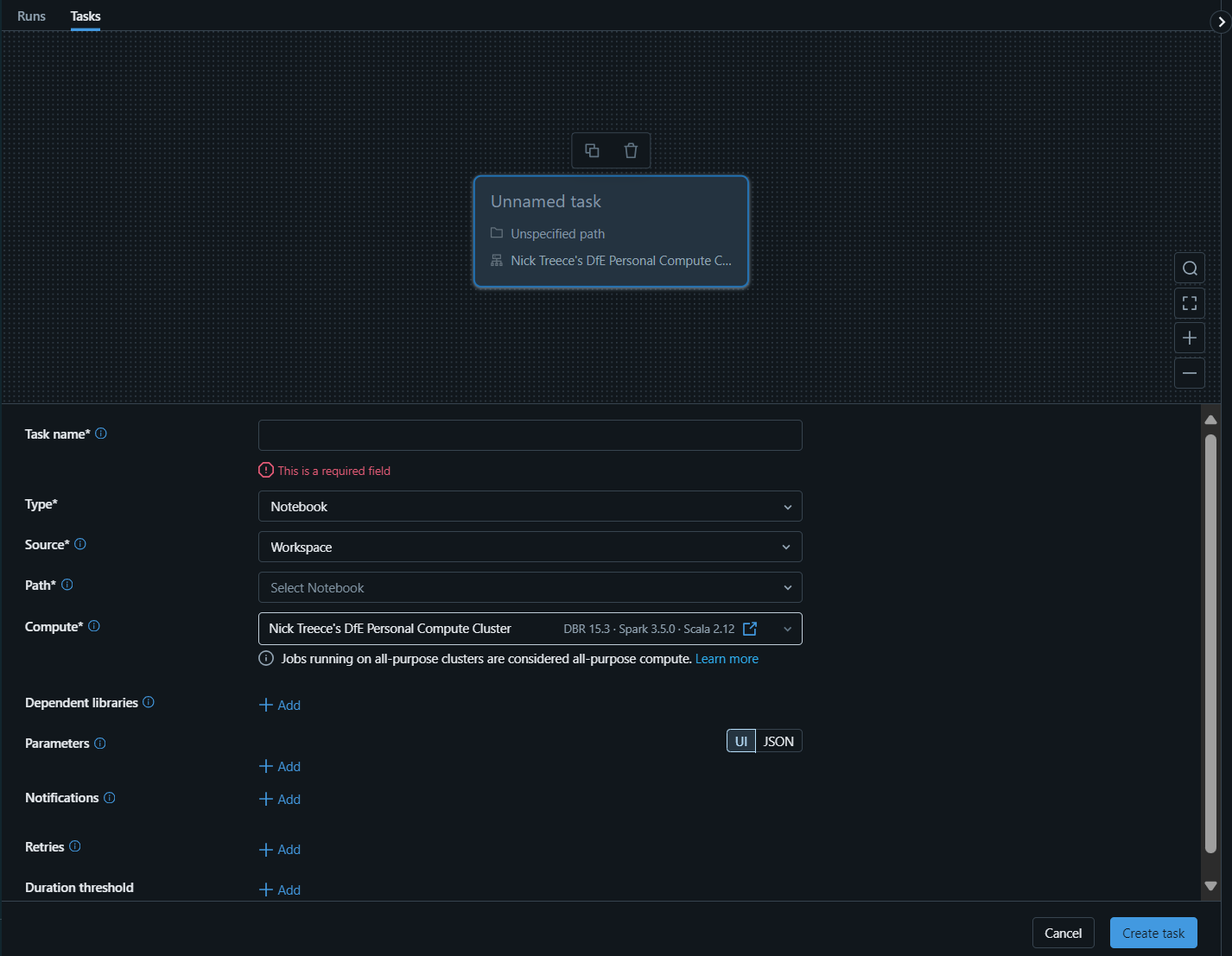
The source by default is set to your workspace, but it is recommended that you use a version controlled Git repository instead. This prevents you changing the code of a notebook during a workflow run as the tasks are sourced from a specific repository version, branch, commit or tag rather than a workbook you may be working on.
During active development it is probably easiest to use your personal compute or a SQL warehouse you have access to.
Once development is complete and the workflow becomes business as usual it may be worth requesting a specific job cluster to be created by the ADA team to be solely responsible for running the workflow.
- Click the ‘Create task’ button to save the details. After this you will be able to add additional tasks.
- Once you begin creating a second task all tasks will now have 2 additional configurations; ‘depends on’, and ‘run if dependencies’.
Depends on - a list of tasks that must be run before the start of this task
Run if dependencies - Instructions for the conditions to run the task based on the dependencies set above. The default option is ‘All succeeded’ but there are also the following options:
- At least one succeeded
- None failed
- All done
- At least one failed
- All failed
- At least one succeeded
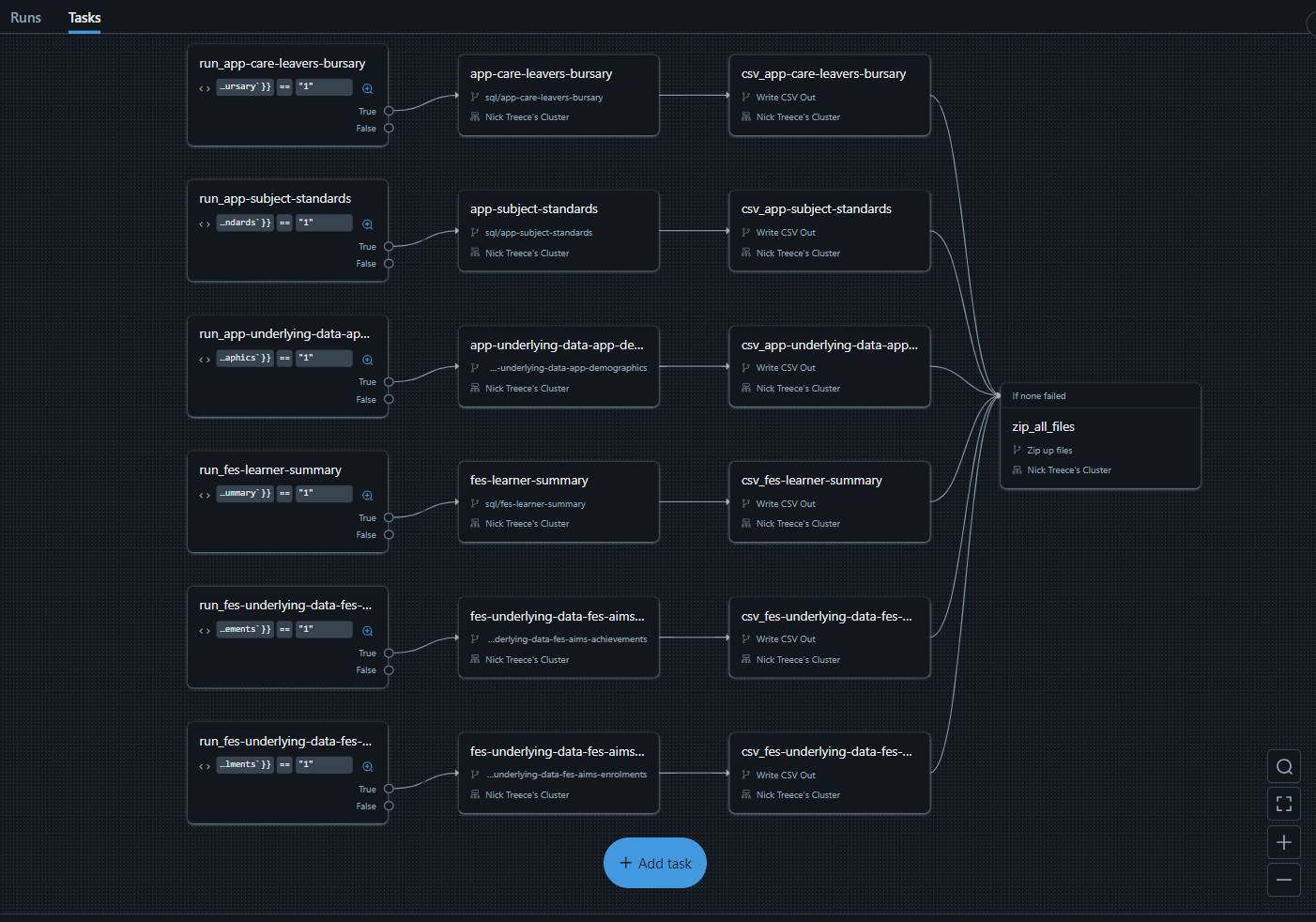
- After setting up a flow of tasks you will be presented with a graphical presentation of the workflow as seen below:
Auditing
Each time a workflow is run, Databricks audits:
- any input parameters
- all outputs
- the success and failure of each task
- when it was run and who by
This makes workflows a very powerful debugging tool as you can refer back to results from previous runs. This means that if your pipeline fails you can review the notebook(s) that failed and troubleshoot the issue.
Workflows that fail also allow you to repair the workflow once you have found and fixed the issue. This prevents having to re-run the whole pipeline from scratch and allows it to pick up from the point where it failed.
Scripted workflows
Another useful aspect of workflows is that they can be defined and ran using code through the Databricks Jobs API.
There is an R library which has been created to interface with the Databricks API, meaning that you can script jobs in R using the Databricks SDK for R package using lists instead of JSON.
For instructions on how to use the Databricks SDK for R package to script workflows see the Scripting Databricks workflows page.