RAP for Statistics
Guidance on the benefits and principles of RAP
What is RAP?
RAP (Reproducible Analytical Pipelines) are a way to create well documented, reproducible, quality analysis using the best tools available to us as analysts.
The “reproducible analysis” part of RAP refers to using tools and best practice to ensure your work can be easily repeated, reviewed and trusted. The ‘pipeline’ part of RAP refers to the process of taking data from its source, through a series of steps, to produce a final output. This could include extraction of data, data preparation and quality assurance.
If you’re new to RAP, Cam’s introductory session for DISD (December 2020) is a great place to start. The slides can be found on GitHub, or you can watch the recording.
RAP implementation
In 2022, the Analysis Function published their RAP strategy, which outlines the expectation that RAP should be “the default approach to analysis in government”. Each department is expected to publish a RAP implementation strategy to explain how they are going to support analysts to embed RAP into their day to day work. You can view the RAP implementation plans for all departments, including DfE on the Analysis Function website.
Most analysts will be using elements of RAP in their work, such as quality assurance and version control, without even thinking about it! For example, writing code that can be re-run at the click of a button. To support the implementation of RAP, cross-government RAP champions have laid out a minimum level of RAP to aim for. In DfE we have adapted these to form our own RAP baseline standards, which are described in detail on this page.
There is currently a clear expectation at DfE that any analyst working in statistics production should know RAP principles and be able to implement them using the recommended tools to meet at least the department’s definitions of “good” and “great” practice.
Benefits of RAP
According to the Analysis Function, using RAP should:
- improve the quality of the analysis
- increase trust in the analysis by producers, their managers and users
- create a more efficient process
- improve business continuity and knowledge management
In DfE, we already have ‘analytical pipelines’ and have done for many years. The aim of RAP is to automate the parts of these pipelines that can be automated, to increase efficiency and accuracy, while creating a clear audit trail to allow analyses to easily be re-run if needed. This will free us up to focus on the parts of our work where our human input can really add value. RAP is something we can use to reduce the burden on us by getting rid of some of the boring stuff, what’s not to like! RAP can also reduce risk through human error, since you will no longer have to copy and paste numbers between different documents or make substantial manual edits to code each time you need to re-run it.
Our scope
We want to focus on the parts of the production process that we have ownership and control over – so for statistics production we are focussing on the process from data sources to publishable data files. This is the part of the process where RAP can currently add the most value - automating the production and quality assurance of our outputs currently takes up huge amount of analytical resource, which could be better spent providing insight and other value adding activity.
![]()
In Official Statistics production we are using RAP as a framework for best practice when producing our published data files, as these are the foundations of our publications moving forward. Following this framework will help us to improve and standardise our current production processes and provide a clear ‘pipeline’ for analysts to follow. To get started with RAP, we first need to be able to understand what it actually means in practice, and be able to assess our own work against the principles of RAP. From there, we can work out what training is needed, if any, and where additional support can help teams to meet the baseline.
In other areas of analysis, we recommend that RAP principles are applied proportionately. Whilst you wouldn’t create a full RAP process for an ad-hoc, you could still version control your code so that it could be reused if similar requests came in, and you should get your code peer reviewed by someone before sending out any results.
Implementing RAP for us will involve combining the use of SQL, R, and clear, consistent version control to increase efficiency and accuracy in our work. For more information on what these tools are, why we are using them, and resources to help upskill in those areas, see our learning resources page.
The collection of, and routine checking of data as it is coming into the department is also an area that RAP can be applied to. We have kept this out of scope at the moment as the levels of control in this area vary wildly from team to team. If you would like advice and help to automate any particular processes, feel free to contact the Statistics Development Team.
Core principles
RAP has three core principles:
Preparing data: Data sources for a publication are stored in the same database
Writing code: Underlying data files are produced using code, with no manual steps
Version control: Files and scripts should be appropriately version controlled
Within each of these principles are separate elements of RAP, which are shown in the diagram below. You can find further information on each of the elements by clicking on the links in the diagram or visiting the RAP start guide page.
RAP in practice
The diagram below highlights what RAP means for us, and the varying levels in which it can be applied in all types of analysis. You can click on each of the hexagons in the diagram to learn more about each of the RAP principles and how to use them in practice.
The expectation is that all statistics publications will meet the department’s baseline implementation of RAP, using the self-assessment tool to monitor their progress. It’s worth acknowledging that some teams are already working around great and best practice levels, and that we appreciate every team’s situation is unique, our guidance is designed to be applicable across all official statistics publications by DfE. Once teams achieve baseline status, their RAP process will be audited.
What is expected
It is expected that all teams’ processes meet all elements of good and great practice as a baseline.
Teams are expected to review their own processes using the publication self-assessment tool and use the guidance on this site to start making improvements towards meeting the core principles if they aren’t already. If you would like additional help to review your processes, please contact the Statistics Development Team.
Teams will start from different places and implement changes at different rates, and in different ways. We do not expect that every team will follow the same path, or even end at the same point. Don’t worry if this seems overwhelming at first, use the guidance here to identify areas for improvement and then tackle them with confidence.
While working to reach our baseline expectation of good and great practice, you can track your progress in the publication self-assessment tool and contact the Statistics Development Team for help and support.
How to assess your publication
The checklist provided in the publication self-assessment tool, shown below, is designed to make reviewing our processes against our RAP levels easier, giving a straightforward list of questions to check your work against. This will flag potential areas of improvement, and you can then use the links on the right hand side to go to the specific section of this page to find more detail and guidance on how to develop your current processes in line with best practice.
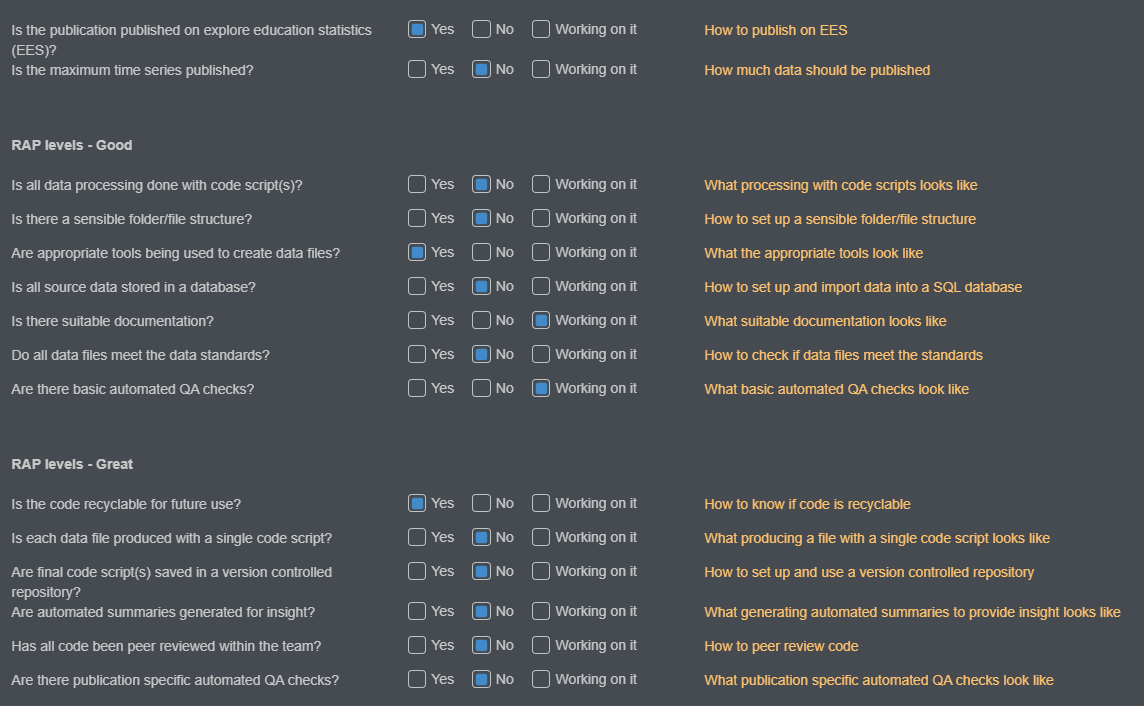
Some teams will already be looking at best practice, while others will still have work to do to achieve the department’s baseline of good and great practice. We know that all teams are starting this from different points, and are here to support all teams from their respective starting positions.
For guidance for how to implement the principles of Reproducible Analytical Pipelines (RAP) into statistics production processes and where to start, see the RAP start guide page.